Apache Kafka를 사용하여 EDA 적용하기
안녕하세요, 여기어때의 결제정산개발팀에서 예약 개발 업무를 맡고 있는 paori 입니다.
이번에 신규 프로젝트를 하면서, 기존에 동기 처리되던 서비스를 비동기로 변경하며 Apache Kafka를 활용하여 Event Driven Architecture를 적용하였습니다. 주니어 중 주니어인 저는 처음 Kafka를 사용해 봤기에, 관련한 내용을 정리해 보려 합니다.
Event Driven Architecture (EDA)
분산된 시스템 간에 사용될 수 있는 아키텍처로, 이벤트가 생성되어 발행되면, 이벤트 로그를 보관하며 해당 이벤트를 필요로 하는 구독자가 이벤트를 받아 처리합니다. 따라서 동기 통신의 요청-응답(request-response) 모델이 아닌 비동기 통신의 발행-구독(pub-sub) 모델을 사용합니다.
이렇게 이벤트 기반의 비동기 처리를 적용하였을 때 느낀 장점은 이번에 작업한 프로젝트를 통해 설명드리겠습니다.
여기어때를 통하여 예약을 하고 나면 예약이 완료되었다는 알림톡 / 문자를 받아볼 수 있습니다. 고객과 마찬가지로 업주에게도 예약에 관한 정보가 통지됩니다. 통지가 되는 템플릿을 예약 상태(결제 완료, 예약 확정, 취소 등)와 고객/업주에 따라 구분하여 다루는 정책을 가지고 있고, 예약에 관련된 데이터는 우리 팀에서 다루고 있기 때문에 예약에 관련된 이벤트가 발생하면 그에 따라 해당하는 템플릿에 예약 데이터들을 담아 통지를 보내도록 해야 합니다.
EDA 적용 전
이를 처리하는 기존의 서비스는 숙박의 경우에는 예약을 담당하는 예약 서비스, 예약 데이터를 템플릿에 매핑하여 다른 팀에서 담당하고 있는 발송 API를 호출하는 통지 서비스가 REST 통신으로 동기 통신을 하고 있었습니다.

통지 서비스를 담당하는 통지 서버가 다운되면 통지 발송에 실패하고 해당 에러가 발생될 것입니다. 동시에, 같이 처리를 하는 숙박 예약 서비스에서도 통지 실패에 대한 에러를 뱉게 됩니다. 통지 서버에서 하는 일을 예약 서비스에서도 하고 있었던 것으로, 책임과 역할이 완벽하게 분리되지 않았던 상태이며 서비스 간 장애 전파의 위험성이 있습니다.
EDA 적용 후
하지만 이 구조를, 예약 관련 이벤트가 발생하였을 때 Kafka 메시지를 발행하고, 통지 서비스에서는 해당 카프카 토픽을 구독하여 메시지가 들어왔을 때 관련 로직을 처리하도록 변경함으로써 1. 책임과 역할을 분리하고 2. 서비스 간 의존도를 낮추었습니다.

EDA 를 적용하면, 3. 메시지를 발행한 서비스의 정보를 (메시지를) 구독하는 서비스는 몰라도 된다는 것이 장점입니다. 그저 메시지가 어떤 이벤트에 따른 것인지만 알면 될 뿐.
덧붙여, 위의 경우(예약/취소/환불 서비스와 통지 서비스)는 성격이 다른 서비스들이기 때문에 통지 서비스에서는 롤백이 필요한 경우에 예약 서비스까지 수정해야 할 부분이 생기지 않지만 MSA 가 적용된 시스템에서 서로 다른 서비스에 걸쳐진 기능을 수행하는 도중에 일관된 commit이나 롤백을 처리해야 하는 경우도 있을 수 있습니다. 그럴 경우에 EDA를 적용하면 Failed 이벤트를 발생시키고 이 전에 보관되어 있던 이벤트 로그 기반으로 롤백을 수행합니다. 4. 재시도가 필요한 경우, 메시지 큐의 Requeue 또는 Dead-Letter Queue 기능을 사용해 재시도 처리를 수행할 수 있습니다.
Apache Kafka
이번 프로젝트에서 EDA를 적용시키기 위하여 Apache Kafka를 사용하였다고 하였는데요, 카프카란 분산 환경에서 대규모 메시지를 안정적으로 전송, 수집, 활용할 수 있도록 도와주는 발행-구독(pub-sub) 모델의 메시지 큐를 가진 이벤트 스트리밍 플랫폼입니다. EDA를 위해 사용되는 기존의 RabbitMQ와 같은 다른 메시지 큐보다 안정적이고 확장성이 좋습니다.
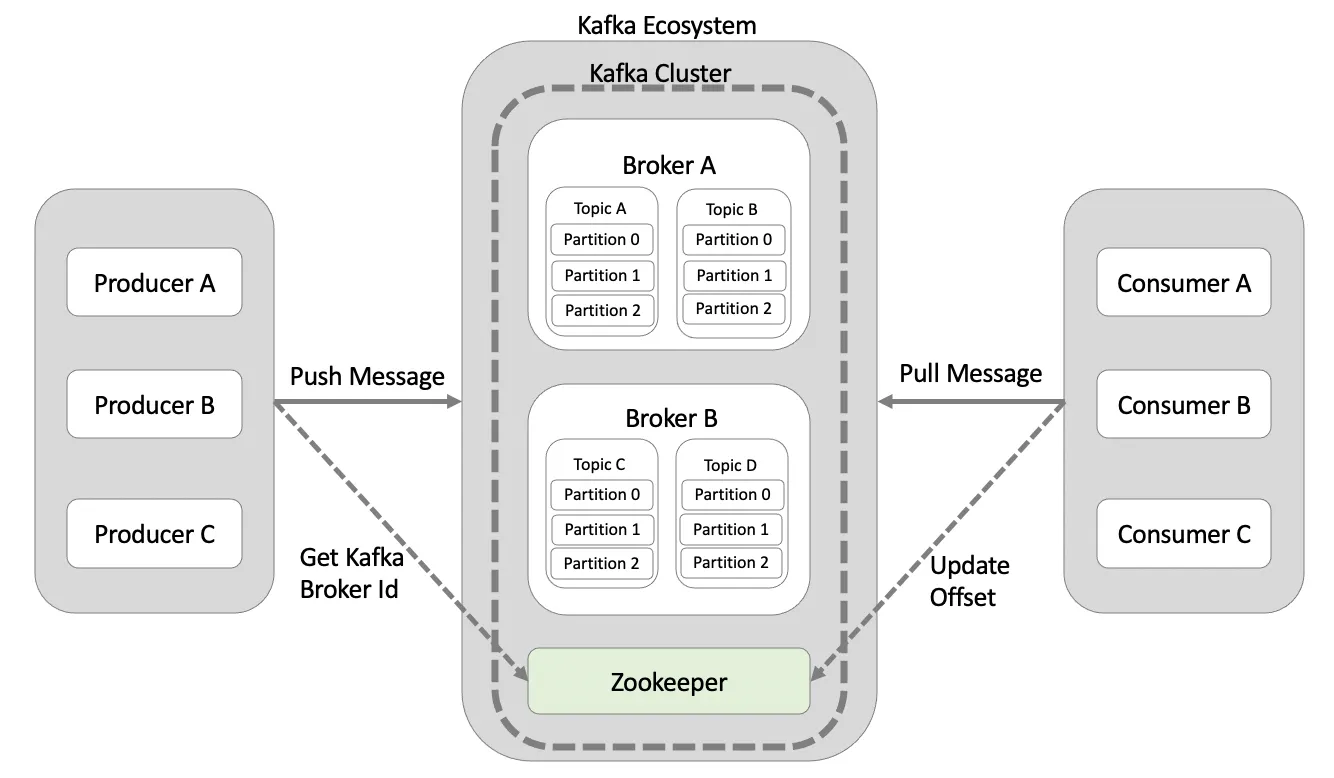
- 카프카 용어
1. 브로커(Broker) : 아파치 카프카 애플리케이션이 설치되어 있는 서버 또는 노드
2. 토픽 (Topic) : 프로듀서(Producer)와 컨슈머(Consumer)들이 카프카로 보낸 자신들의 메시지를 구분하기 위한 고유의 이름입니다.
3. 프로듀서 (Producer) : 메시지를 생산하여 브로커의 토픽 이름으로 보내는 서버 또는 애플리케이션
4. 컨슈머 (Consumer) : 브로커의 토픽 이름으로 저장된 메시지를 가져가는 서버 또는 애플리케이션
5. 파티션 (Partition) : 병렬처리가 가능하도록 토픽을 나눌 수 있고, 많은 양의 메시지 처리를 위해 파티션의 수를 늘려줄 수 있습니다.
6. 주키퍼 (ZooKeeper) : 분산 애플리케이션을 위한 코디네이션 시스템입니다. 분산된 애플리케이션의 정보를 중앙에 집중하고 구성 관리, 그룹, 네이밍, 동기화 등의 서비스를 수행합니다.위의 아키텍처를 가진 카프카의 특징은 다음과 같습니다.
- 멀티 프로듀서, 멀티 컨슈머
: 카프카의 중앙 집중형 구조로 인하여 하나의 프로듀서가 여러 개의 토픽 생성이 가능하고, 하나의 컨슈머가 여러 개의 토픽을 받을 수 있습니다. - 디스크에 메세지 저장하고 유지
: 컨슈머가 메시지를 읽어도 정해져 있는 보관 주기 동안에는 디스크에 메시지를 저장해둡니다. 그렇기 때문에 트래픽이 일시적으로 많아지거나 컨슈머에 오류가 있더라도 메시지 손실 없이 작업이 가능합니다. (메시지의 영속성 확보) - 확장성
: 하나의 카프카 클러스터는 3대의 브로커로 시작하기 때문에 수십 대의 브로커로 무중단 확장이 가능합니다.
또한, 하나의 토픽에 파티션을 여러 개 지정할 경우에 프로듀서는 발행하는 메시지에 포함된 메시지 키 또는 메시지 값에 따라서 파티션의 위치를 결정하는데요, 키가 없는 경우에는 각각의 파티션에 Round-robin 방식으로 순차적 배분을 합니다. 컨슈머는 메시지를 가져올 때마다 오프셋 정보를 커밋 하기 때문에 메시지를 어디까지 가져왔는지도 확인이 가능합니다. 하지만, 여러 개의 파티션을 사용할 경우에 동일 파티션 내에서는 순서가 보장되지만, 파티션과 파티션 사이에서는 순서를 보장하지 못합니다.
토픽에 쌓이는 메시지의 속도를 컨슈머가 가져가는 속도를 따라가지 못하는 경우도 있는데, 이럴 경우에 밀리는 메시지의 갯수를 lag이라고 합니다.
프로젝트를 하면서 컨슈머의 애플리케이션이 제대로 떠 있지 않은 경우에 lag이 증가하는 것을 직접 확인할 수 있었고, 정상적으로 다시 메시지를 구독할 수 있게 되었을 경우에는 roll-up이 되어 밀린 메시지들 처리까지 되는 것을 볼 수 있었습니다.
메시지를 구독하는 컨슈머 설정에서는 GroupId로 컨슈머 그룹을 지정할 수도 있는데요, 이는 여러 컨슈머 서버/애플리케이션을 그룹으로 묶어서 하나의 토픽에서 오는 메시지들을 파티션을 나눠 가져 처리할 수 있습니다.

실제로, 개발 환경에서 이전 통지 서버는 메시지는 소비하지만, 실제 발송은 이루어지지 않는 서버 / 신규 통지 서버는 실제 발송까지 이루어지는 서버 가 있었습니다. 두 서버가 모두 정상 동작 하고 있을 경우에 카프카 설정을 같은 GroupId (위 그림에서는 place-noti)로 설정하면 두 개의 서버는 구독하는 토픽의 파티션을 나눠 가지기 때문에 partition 1, 3를 거치는 메시지는 실제 발송이 되지 않았고 partition 2, 4를 거치는 메시지는 실제 발송까지 이루어졌습니다.
따라서 하나의 컨슈머가 처리하기에 너무 많은 메시지들이 생길 경우에는 lag이 쌓이고 지연이 발생되며 장애가 발생될 가능성도 높아지기 때문에 같은 컨슈머 그룹 안에 컨슈머를 더 추가하여 토픽에 저장된 데이터를 읽어가는 속도를 높일 수 있습니다. ( 이 과정을 Rebalancing이라고 합니다. )
위에서 언급했던 EDA에서 재시도 처리를 하기 위한 기능 중, 카프카의 dead letter queue는 이름에서도 알 수 있듯이 실패한 레코드를 보관하는 별도의 큐입니다. 카프카는 dead letter queue로 원천 데이터가 보관된 토픽이 아닌, 별도의 토픽으로 설정하고 실패한 메시지의 메타정보(토픽, 파티션, 오프셋, Exception 내용)도 함께 저장하여 전송 에러 발생 시에도 메시지가 보관되어 다시 처리할 수 있습니다.
이러한 특징들로 보아, 카프카는 대용량/분산 처리에 특화된 이벤트 기반 시스템이며, 손실 방지에 최적화되어있다는 것을 알 수 있습니다.
Kafka Consumer 개발하기
우리 팀에서는 예약이 완료되면 PaidOrder, 확정되면 CompletedOrder, 취소되면 Cancel 토픽으로 각각 메시지를 발행합니다. (승인예약 업체의 경우 결제완료의 시점과 예약확정의 시점이 다르기 때문에 위와 같이 처리합니다.)
각 토픽의 파티션은 3개씩 구성되어 있으며, 카프카 운영 모니터링 어플리케이션 AKHQ를 통하여 토픽 리스트, 각 토픽 별로 연결된 컨슈머 그룹, 실시간으로 발행되고 구독하는 메시지, 컨슈머 별 lag 정보 등을 확인하고 있습니다.
이번 프로젝트에서 통지 서비스가 PaidOrder, CompletedOrder, Cancel 세 개의 토픽을 구독하도록 하였는데요, 소스 코드를 간략히 정리해보겠습니다.
Spring Boot에 kafka 의존성을 추가했습니다.
구독할 토픽 이름과 컨슈머 groupId 등을 설정해주었습니다. 추가로 보안 관련 설정도 해 주었으나, 해당 부분은 생략하도록 하겠습니다.
세 개의 토픽은 모두 같은 설정을 따르므로 두 개의 토픽에 대한 코드는 생략하도록 하겠습니다. 컨슈머에 대한 설정 정보를 담을 Consumer 모델을 생성하였습니다.
ConcurrentKafkaContainerFactory 클래스를 생성하고 ConsumerFactory 인터페이스를 내부 멤버 변수에 set하고 빈으로 등록하기 위하여 작성하였습니다.
@KafkaListener annotation을 붙여서 KafkaConsumerConfig.java 에서 설정해 둔 ConcurrentKafkaListenerContainerFactory로 컨테이너를 연결하여 사용하였습니다.
참고로, Spring에서 컨테이너 팩토리는 KafkaListenerContainerFactory, ConcurrentKafkaListenerContainerFactory 두 가지가 제공됩니다. 전자는 동시성 처리를 지원히지 않고, 후자는 동시성 처리를 지원하기 때문에 후자를 사용할 경우에는 하나의 컨슈머에서 여러개의 파티션을 연결하여 멀티 소비가 가능합니다.
이렇게 하여 세 개의 토픽을 구독하여 메시지를 받는 것을 확인할 수 있었습니다.
그렇다면 EDA를 위해서는 Kafka만이 답인가? — 그렇지 않습니다.
물론 카프카의 성능은 뛰어나지만, 메시지의 consume 순서는 단일 파티션이 아닐 경우 보장되지 않기 때문에 대기열의 개념으로 queuing 처리가 필요한 경우 (순서가 중요한 경우)에는 SQS나 RabbitMQ로 싱글 큐를 사용하는 것이 좋습니다.
하나의 파티션만 사용할 경우에는 순서 보장이 되겠지만, 그럴 경우에는 분산 처리가 불가능하므로 카프카를 이용하는 큰 목적이 사라지며, 다른 플랫폼들이 더 좋은 성능을 낼 수 있습니다.
따라서
- 높은 처리량 및 고성능/분산/스케일 아웃이 중요한 경우
- 가용성이 높아야 하는 경우
- 메시지 영속성이 필요한 경우에는 Kafka를, 메시지의 순서가 보장되어야 하는 경우나 메시지 영속성이 필요하지 않은 경우에는 RabbitMQ와 같은 다른 플랫폼을 사용하는 것을 고려해야 합니다.
우리 팀에 와서 Event Driven 방식으로 개발하는 것도, Kafka를 다뤄보는 것도 처음이었는데, 이런저런 에러를 마주하면서 kafka의 분산처리나 손실 방지 가 동작하는 것을 직접 경험할 수 있어서 흥미로웠던 프로젝트였습니다.
프로젝트 및 카프카 지식 습득에 도움을 주신 우리 팀원들 감사합니다. (하트)
